
Any good stats book has to cover a bit of basic probability. That's the purpose of Chapter 5 of Using R for Introductory Statistics, starting with a few definitions:
- Random variable
- A random number drawn from a population. A random variable is a variable for which we define a range of possible values and a probability distribution. The probability distribution specifies the probability that the variable assumes any value in its range.
The range of a discrete random variable is a finite list of values. For any value k in the range, 0 ≤ P(X=k) ≤ 1. The sum over all values k in the range is 1.
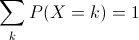
R sample function implements these definitions. For example, let's ask R to create a six-sided die for us.
p.die <- rep(1/6,6)
sum(p.die)
Now, let's roll it 10 times.
die <- 1:6
sample(die, size=10, prob=p.die, replace=T)
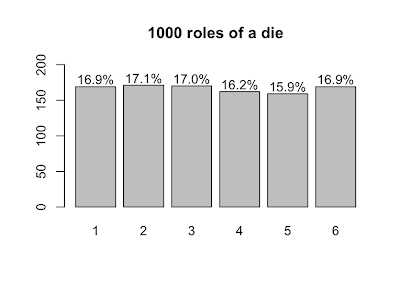
Now, let's roll 1000 dice and plot the results.
s <- table(sample(die, size=1000, prob=p.die, replace=T))
lbls = sprintf("%0.1f%%", s/sum(s)*100)
barX <- barplot(s, ylim=c(0,200))
text(x=barX, y=s+10, label=lbls)
- Expected value
- Expected value (or population mean) of a discrete random variable X is the weighted average of the values in the range of X.
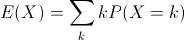
In the case of our six-sided die, the expected value is 3.5, computed like so:
sum(die*p.die)
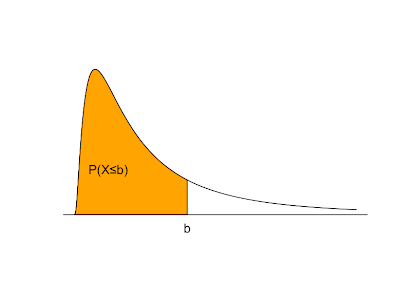
Things change a bit when we move from discrete to continuous random variables. A continuous random variable is described by a probability density function. If f(x) is the probability density of a random variable X, P(X≤b) is the area under f(x) and to the left of b. The total area under f(x) = 1. f(x) ≥ 0 for all possible values of X. P(X>b) = 1 - P(X≤b). The expected value is the balance point where exactly half of the total area under f(x) is to the right and half is to the left.
A random sample is a sequence of independent identically distributed random variables. A value derived from a random sample, such as sample mean, sample standard deviation, etc. is called a statistic. When we compute statistics of samples, our hope is that the sample statistic is not too far off from the equivalent measurement of the whole population.
The interesting thing is that derived statistics are also random variables. If we role our die several times, we have taken a random sample of size n. That sample can be summarized by computing its mean, denoted by X bar.
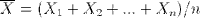
The sample mean is, itself, a random variable with its own distribution. So, let's take a look at that distribution. Because we'll use it later, let's define a function that generates a bunch of samples of size n and computes their means. It returns a vector of sample means.
generate.sample.means <- function(n) {
sample.means <- numeric()
for (i in 1:1000) {
sample.means <- append(sample.means, sum(sample(die, size=n, prob=p.die, replace=T))/n)
}
return (sample.means)
}
sample.means <- generate.sample.means(100)
plot(density(sample.means), main="Distribution of sample means",xlab="sample mean", col="orange")
Not coincidentally, it fits pretty closely to a normal distribution (dashed blue line). It's mean is about the same as the parent population, namely right around 3.5. The standard deviation of the sample means can be derived by dividing the standard deviation of the parent population by the square root of the sample size: σ / √ n.
Let's compare the mean and sd of our sample with predicted values. We compute the standard deviation of our parent population of die rolls by squaring the deviation from the mean for each possible value and averaging that. Dividing that by the square root of our sample size gives the predicted sd of our sample means, about 0.17, which is about spot on with the actual sd.
> mean(sample.means)
[1] 3.49002
> sd(sample.means)
[1] 0.1704918
> sqrt(sum( (1:6-3.5)^2 ) / 6) / sqrt(100)
[1] 0.1707825
To overlay the normal distribution on the plot above, we used R's dnorm function like this:
x = seq(3,4,0.01)
lines(x=x,y=dnorm(x,mean=3.5,sd=0.1707825), col=rgb(0x33,0x66,0xAA,0x90,maxColorValue=255), type="l", lty=2)
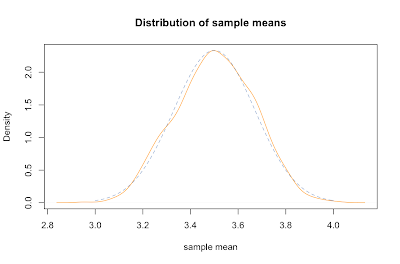
Inspection of the formula for the standard deviation of sample means supports our common sense intuition that a bigger sample will more likely reflect the whole population. In particular, as the size of our sample goes up, our estimated mean is more likely to be closer to the parent population mean. This idea is known as the law of large numbers. We can show that it works by creating similar plots with increasing n.
sample.means <- generate.sample.means(100)
plot(density(sample.means), main="Distribution of sample means", xlab="sample mean", col="yellow", xlim=c(3.2,3.8), ylim=c(0,8))
sample.means <- generate.sample.means(500)
lines(density(sample.means), col="orange")
sample.means <- generate.sample.means(1000)
lines(density(sample.means), col="red")
legend(3.6,7,c("n=100","n=500","n=1000"), fill=c("yellow", "orange", "red"))
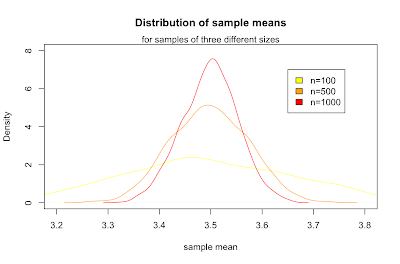
What we've just discovered is the central limit theorem, which states that for any parent population with mean μ and standard deviation σ, the sampling distribution for large n is a normal distribution with mean μ and standard deviation σ / √ n. Putting that in terms of the standard normal distribution Z gives:
It's a little surprising that the normal distribution arises out of a means of samples from a discrete uniform distribution. More surprisingly, samples from any parent distribution give rise to the normal distribution in exactly the same way. Next, we'll look at several widely used families of distributions and R's functions for working with them.
Notes
The graph above shaded in orange serving as an example probability density function is produced with the following R code:
plot(x=c(seq(0,5,0.01)), y=c(dlnorm(x=seq(0,5,0.01),meanlog=0,sdlog=1)), type="l", xlab='', ylab='', yaxt="n", xaxt="n", bty="n")
polygon(x=c(seq(0,2,0.01),2), y=c(dlnorm(x=seq(0,2,0.01),meanlog=0,sdlog=1),0), col="orange")
mtext('b', at=c(2), side=1)
text(0.6,0.2,"P(X≤b)")
abline(c(0,0),c(0,5))
More Using R for Introductory Statistics































 R Bloggers
R Bloggers