The Sorger lab at Harvard published a piece in the February 2011 Nature Methods that shows some really clear thinking on the topic of designing data storage for biological data. That paper, Adaptive informatics for multifactorial and high-content biological data, Millard et al., introduces a storage system called SDCubes, short for semantically typed data hypercubes, which boils down to HDF5 plus XML. The software is hosted semanticbiology.com.
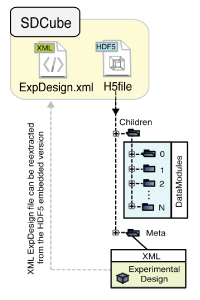
This two part strategy applies HDF5 to store high-dimensional numeric data efficiently, while storing sufficient metadata in XML to reconstruct the design of the experiment. This is smart, because with modern data acquisition technology, you're often dealing with volumes of data where attention to efficiency is required. But, experimental design, the place where creativity directly intersects with science, is a rapidly moving target. The only hope of capturing that kind of data is a flexible semi-structured representation.
This approach is very reminiscent, if a bit more sophisticated, than something that was tried in the Baliga lab called EMI-ML, which was roughly along the same lines except that the numeric data was stored in tab-separated text files rather than HDF5. Or to put it another way, TSV + XML instead of HDF5 + XML.
Another ISB effort, Addama (Adaptive Data Management) started as a ReSTful API over a content management system and has evolved into a ReSTful service layer providing authentication and search and enabling access to underlying CMS, SQL databases, and data analysis services. Addama has ambitions beyond data management, but shares with SDCube the emphasis on adaptability to the unpredictable requirements inherent in research by enabling software to reflect the design of individual experiments.
There's something to be said for these hybrid approaches. Once you start looking, you see a similar pattern in lots of places.
- NoSQL - SQL hybrids
- SQL - XML hybrids. SQL-Server, for one, has great support for XML enabling XQuery and XPath mixed with SQL.
- Search engines, like Solr, are typically used next to an existing database
- Key/value tables in a database (aka Entity–attribute–value)
Combining structured and semi-structured data allows room for flexibility where you need it, while retaining RDBMS performance where it fits. Using HDF5 adapts the pattern for scientific applications working with vectors and matrices, structures not well served by either relational or hierarchical models. Where does that leave us in biology with our networks?. I don't know whether HDF5 can store graphs. Maybe we need a triple hybrid relational-matrix-graph database.

By the way, HDF5 libraries exist for several languages. SDCube is in Java. MATLAB can read HDF5. There is an HDF5 package for R, but it seems incomplete.
Relational databases work extremely well for some things. But, flexibility has never been their strong point. They've been optimized for 40 years, but shaped by the transaction processing problems they were designed to solve, and they just get awkward for certain uses, to name some - graphs, matrices and frequently changing schemas.
Maybe, before too long the big database vendors go multi-paradigm and we'll see matrices, graphs, key-value pairs, XML and JSON as native data structures that can be sliced and diced and joined at will right along with tables.
More information
- Quantitative data: learning to share, an essay by Monya Baker in Nature Methods, describes how "Adaptive technologies are helping researchers combine and organize experimental results."






 R Bloggers
R Bloggers
No comments:
Post a Comment